
개발 기록
DB Index 본문
인덱스 유무에 따른 성능 차이
select * from customer where first_mname = 'minsoo';first_name에 인덱스가 없다면
- full scan (=table scan) 으로 찾음
- O(N)
first_name에 인덱스가 있다면
- full scan보다 빠르게 찾음
- O(logN) (B-tree based index일때)
인덱스를 쓰는 이유
- 조건을 만족하는 튜플들을 빠르게 조회
- 빠르게 정렬, 그룹핑
인덱스 생성 문법
- 이미 만들어진 테이블에 생성
CREATE INDEX index_name ON table(column)
CREATE UNIQUE INDEX index_name ON table(column1, column2)
- 테이블 만들때 생성
CREATE TABLE table(
id INT PRIMARY KEY,
...
INDEX index_name (column)
UNIQUE INDEX index_name (column1, column2)
);--> 대부분의 RDBMS에서는 primary key에 index가 자동 생성됨
- 인덱스 정보 조회
SHOW INDEX FROM table;
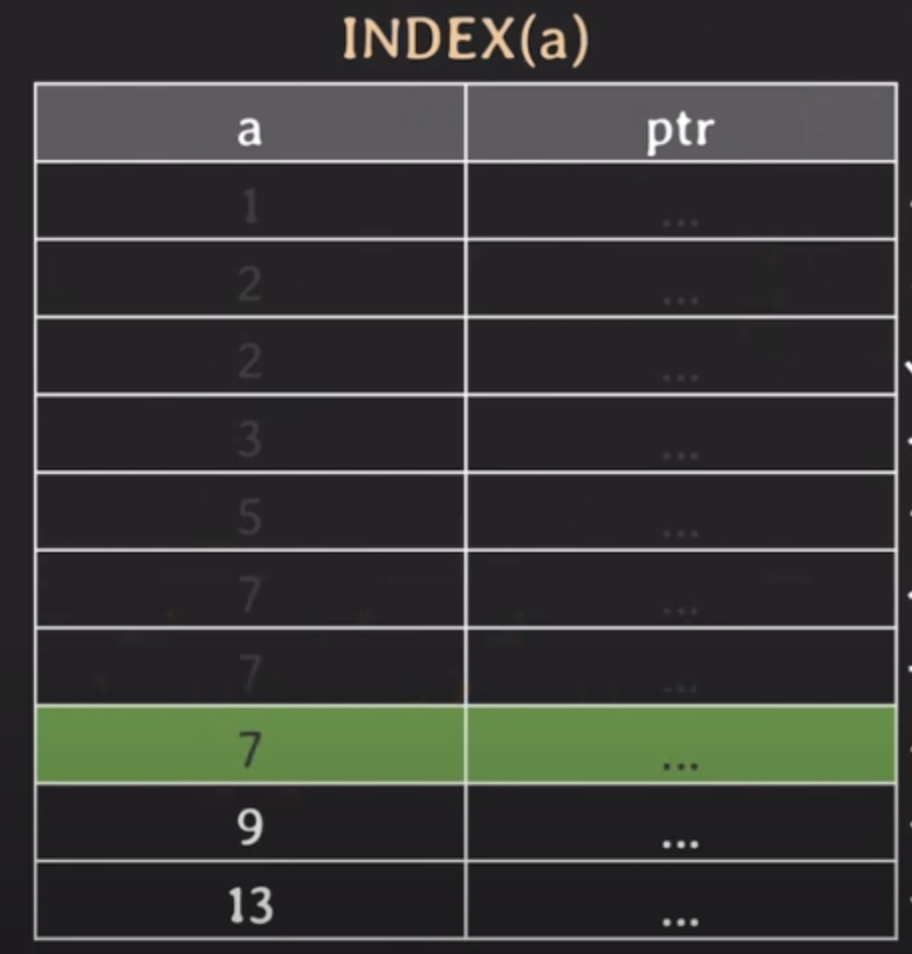
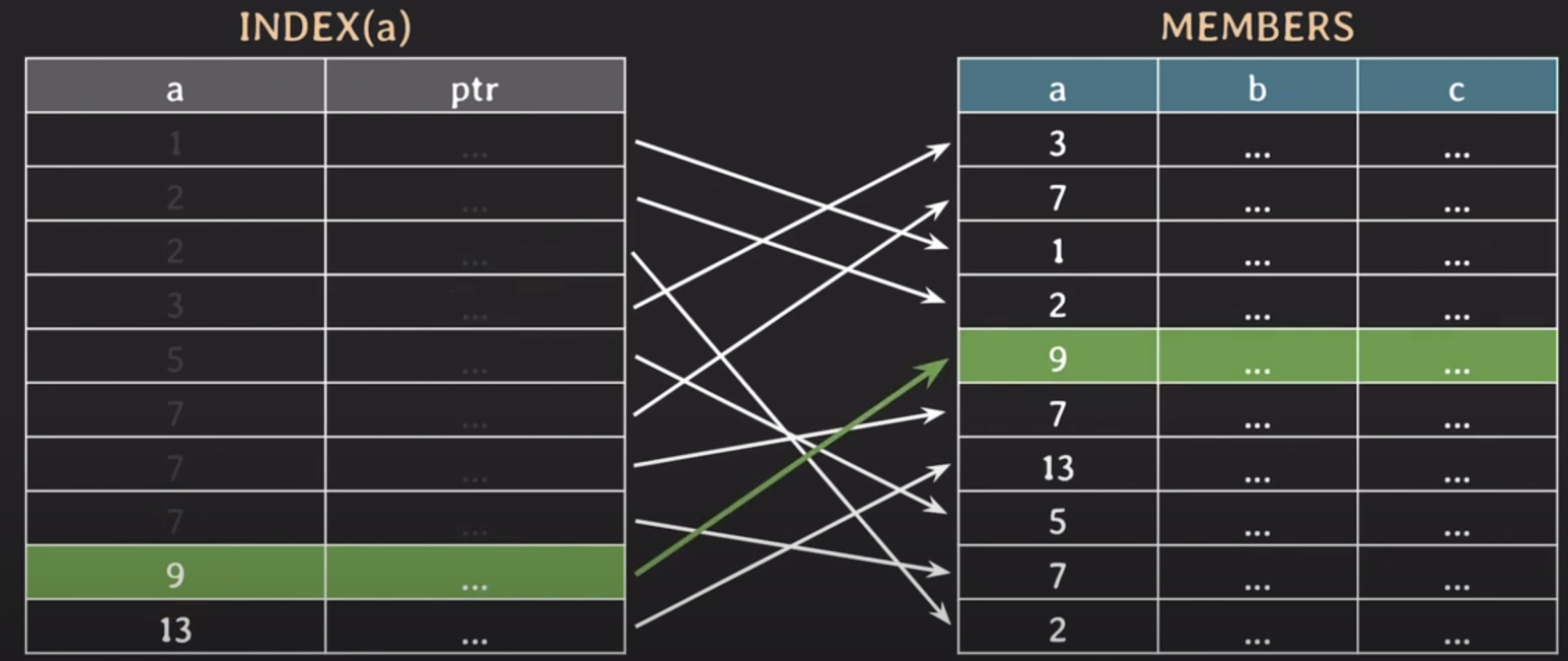
B-tree 인덱스 동작 방식

- ptr : 인덱스와 실제 튜플을 가르키는 연결고리 역할
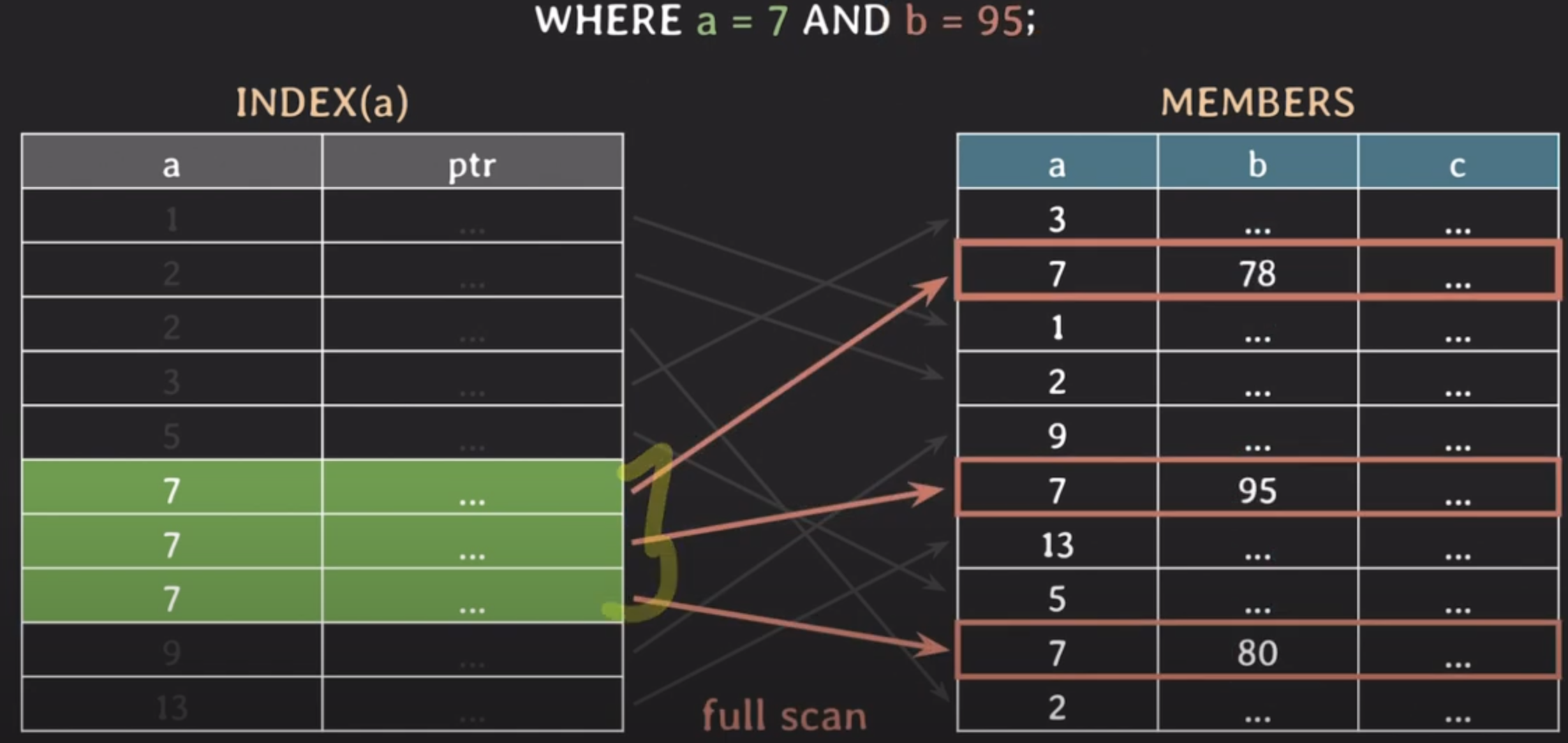
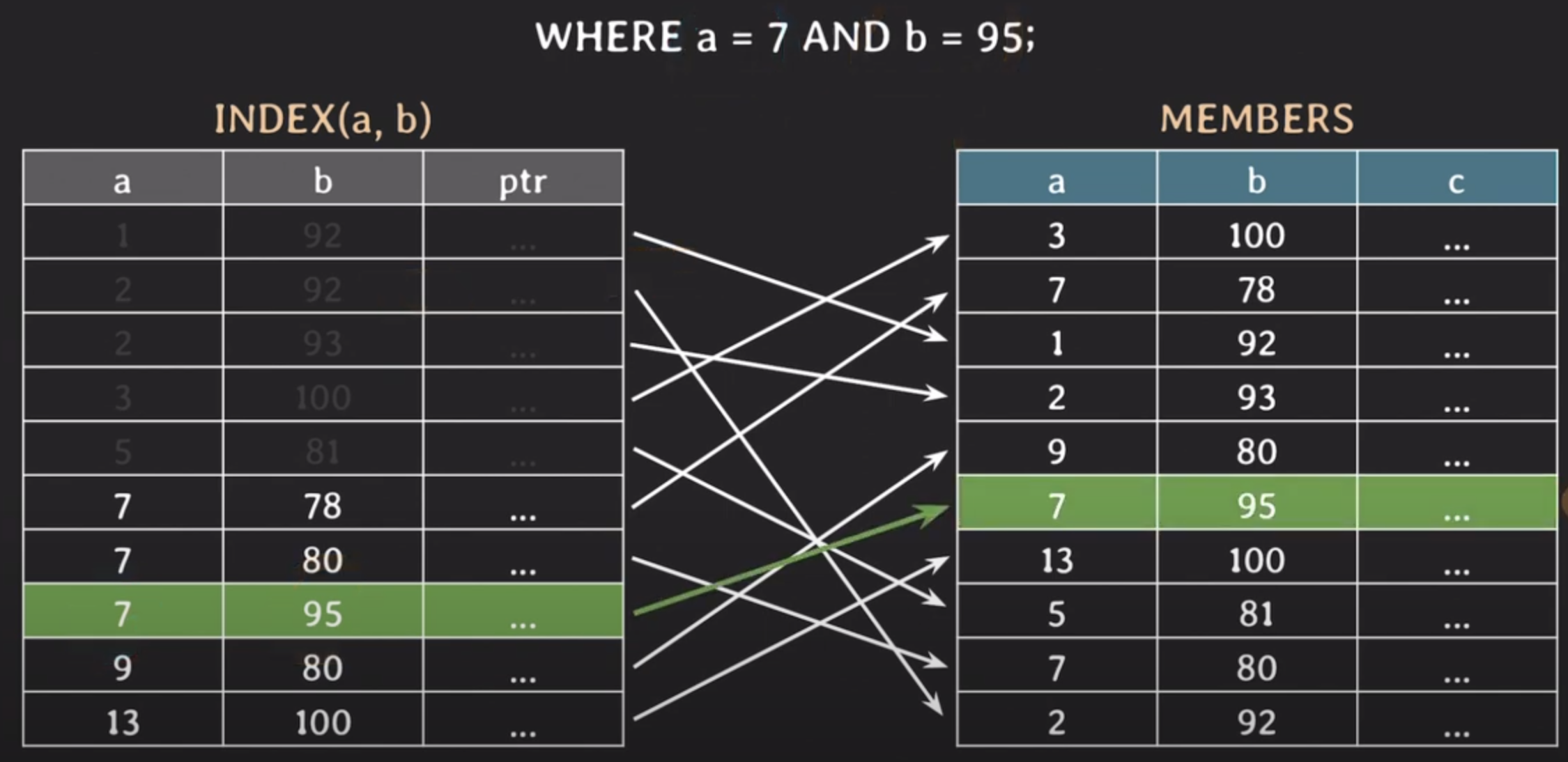
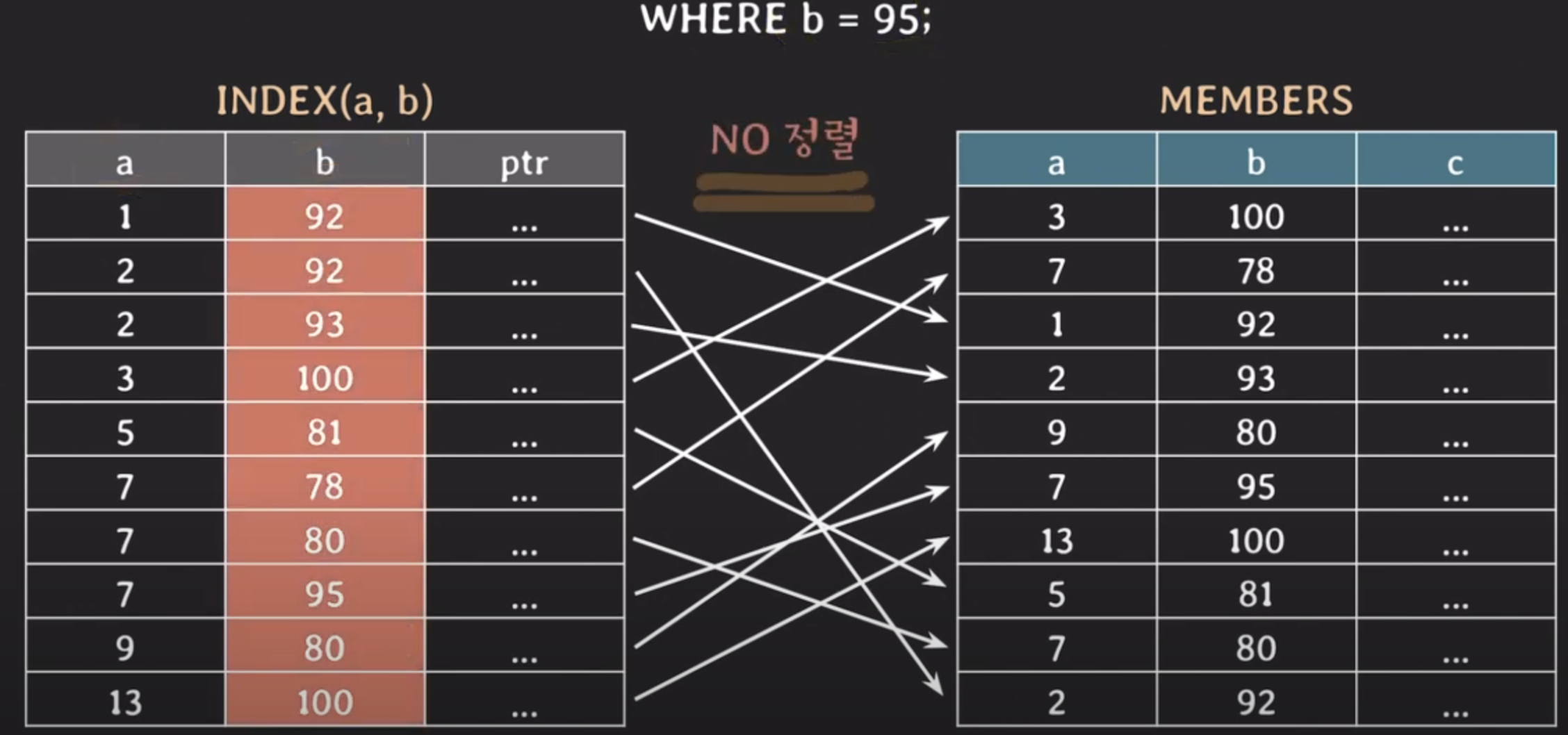
사용 쿼리에 맞처서 적절히 인덱스를 걸어줘야함
멀티컬럼 인덱스일때는 순서도 중요
쿼리가 어떤 인덱스를 쓰는지 확인
optimizer가 알아서 인덱스를 적절하게 선택 해줌 (직접 지정도 가능)
EXPLAIN
SELECT * FROM table WHERE id = 1;
인덱스가 많을 때 단점
- 테이블에 데이터 cud할때마다 index도 변경 발생 : b-tree 기반일 때는 구조가 변경되어 오버헤드 발생
- 추가적인 저장 공간 차지

-> 불필요한 index 만들지 말기
covering index

hash index
- hash table을 사용하여 index 구현
- 시간 복잡도 O(1)
- rehashing에 대한 부담 (해시 테이블 사이즈 증가)
- 동일성 비교만 가능, 범위 비교 불가능
- 멀티컬럼 인덱스의 경우 일부가 아닌 전체 attributes에 대한 조회만 가능
full scan이 더 좋은 경우
- table에 데이터가 조금 있을 때 (몇 십, 몇 백건 ..)
- 테이블의 많은 데이터를 조회할때
출처